
Menu
Carolina é um corpus com um volume robusto de textos em Português Brasileiro contemporâneo (1970-2021), com informações de procedência e tipologia. O corpus está disponível em acesso aberto, para download gratuito, desde 8 de março de 2022.
A versão atual, Ada 1.2 (8 de março de 2023), tem 823 milhões de tokens, mais de dois milhões de textos e mais de 11 GBs.
Contexto
O C4AI-USP tem a missão de produzir pesquisa avançada em Inteligência Artificial no Brasil. O Projeto de Processamento de Linguagem Natural - NLP2 é um dos desafios do C4AI, e tem como objetivo geral desenvolver sistemas que avancem o estado da arte do Processamento de Linguagem Natural para o português brasileiro, atingindo um novo patamar em qualidade de geração e desempenho em relação ao que existe hoje.
O NLP2 do C4AI-USP está atualmente construindo vários corpora, entre eles o Carolina, o CORAA, Corpus de Áudios Anotados de Português Falado e o Portinari, Corpus Anotado do Português. O Carolina será um corpus do português contemporâneo para amplo uso, inclusive servindo como uma “nave-mãe” com relação aos demais corpora produzidos no C4AI-USP (englobando as transcrições de áudio do CORAA, os textos brutos não rotulados do Portinari e outros corpora futuros).
Leia mais sobre o desafio NPL2 na página do Projeto no C4AI.
Fundamentos
O Corpus Carolina é concebido com uma metodologia original que denominamos WaC-wiPT: Web as Corpus com informações de Proveniência e Tipologia.
Consideramos a proveniência um aspecto crucial a se aspirar em corpora baseados na web, combinada à tipologia e ao gerenciamento de equilíbrio. Além de facilitar o cumprimento dos direitos autorais e a rotulagem tipológica, ela permite responder a perguntas sobre a origem dos textos e aumenta o escopo de uso do corpus.
O trabalho inicial da equipe do Carolina buscou abordar a tipologia textual em um sentido amplo, livre de um compromisso teórico estrito, como uma ferramenta metodológica crucial no desenvolvimento de um acervo de textos de tamanho tão significativo - permitindo a organização das buscas, da seleção e do balanceamento dos textos.
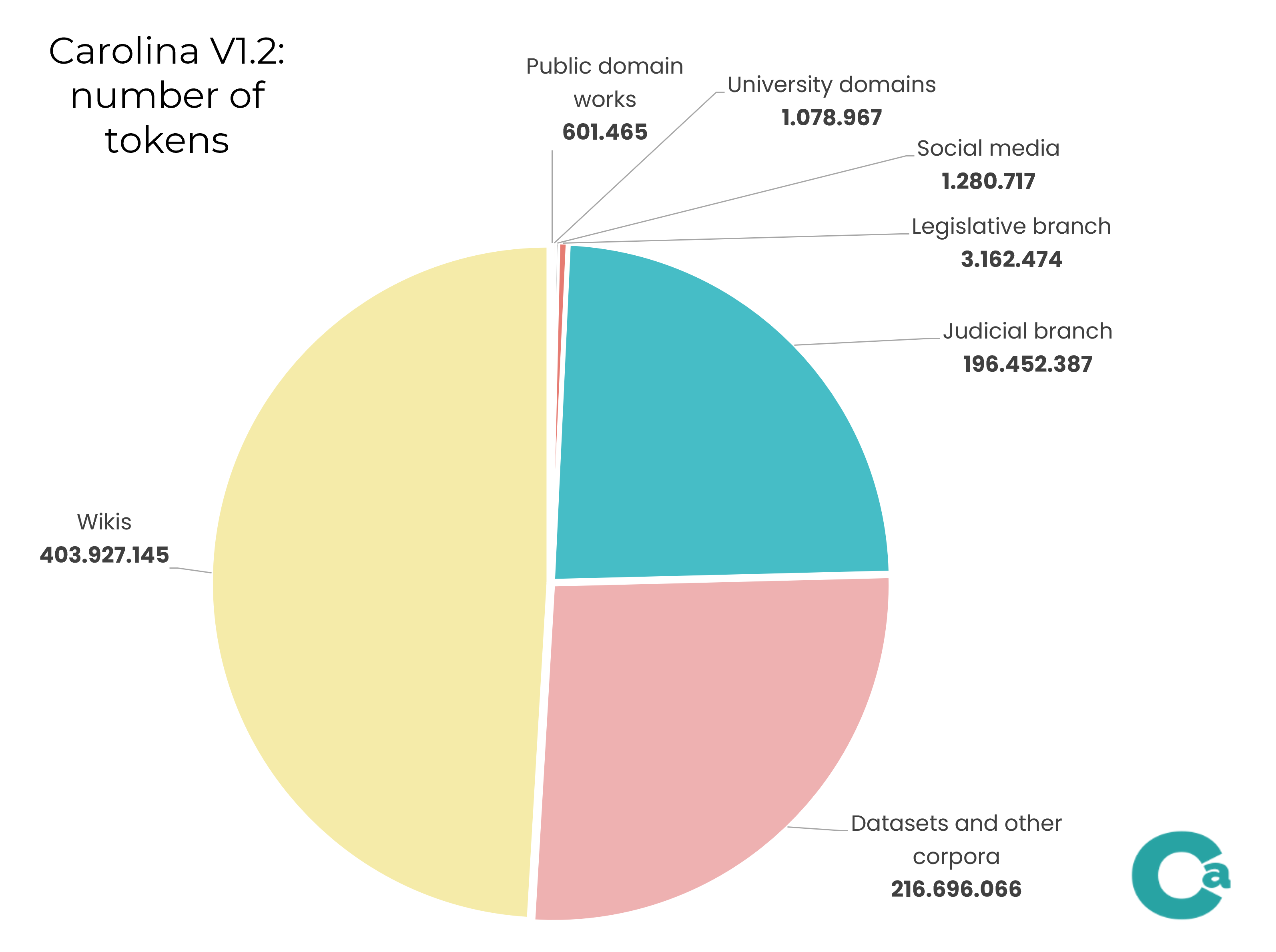
A versão atual do corpus, com cerca de 830 milhões de tokens e 2 milhões de textos, inclui material do âmbito judiciário e legislativo brasileiros, obras literárias em domínio público, textos jornalísticos, textos de redes sociais e wikis, e textos já publicados em outros corpora.
A v1 Ada (1.0, 1.1 ou 1.2) ainda não representa um universo balanceado quanto à procedência dos textos e sua tipologia ampla, como mostram os dados no gráfico ao lado, relativo à versão 1.2. Observe-se que a v1 corresponde apenas a uma parte dos documentos já prospectados e ainda em tratamento pela equipe.
Equipe
Professores doutores
Marcelo Finger , IME-USP
Maria Clara Paixão de Sousa , FFLCH-USP
Cristiane Namiuti , PPGLin-UESB
Vanessa Martins do Monte , FFLCH-USP
Doutorandos
Aline Silva Costa , PPGLin-UESB
Felipe Ribas Serras , IME-USP
Mestrandos
Guilherme Lamartine de Mello , IME-USP
Mariana Lourenço Sturzeneker , FLP-FFLCH-USP
Maria Clara Ramos Morales Crespo , FLUL-ULisboa
Raquel de Paula Guets , FLP-FFLCH-USP
Renata Morais Mesquita , FLP-FFLCH-USP
Graduandas e graduadas
Mariana Marques da Silva , FFLCH-USP
Maria Lina de Souza Jeannine Rocha , FFLCH-USP
Mayara Feliciano Palma , FFLCH-USP
Publicações relacionadas
Sturzeneker, Mariana Lourenço; Crespo, Maria Clara Ramos Morales; Rocha, Maria Lina de Souza Jeannine; Finger, Marcelo; Paixão de Sousa, Maria Clara; Monte, Vanessa Martins do; Namiuti, Cristiane. ‘Carolina’s Methodology: building a large corpus with provenance and typology information’. Proceedings of the Second Workshop on Digital Humanities and Natural Language Processing (2nd DHandNLP 2022). CEUR-WS, Vol. 3128, 2022. Available at http://ceur-ws.org/Vol-3128.
Crespo, Maria Clara Ramos Morales; Rocha, Maria Lina de Souza Jeannine; Sturzeneker, Mariana Lourenço; Serras, Felipe Ribas; Mello, Guilherme Lamartine de; Costa, Aline Silva; Palma, Mayara Feliciano; Mesquita, Renata Morais; Guets, Raquel de Paula; Silva, Mariana Marques da; Finger, Marcelo; Paixão de Sousa, Maria Clara; Namiuti, Cristiane; Martins do Monte, Vanessa. Carolina: a General Corpus of Contemporary Brazilian Portuguese with Provenance, Typology and Versioning Information. Manuscript. September, 2022.
'Carolina'
Carolina Michaelis em foto de 1876
O Corpus Carolina recebeu esse nome em homenagem a Carolina Michaelis de Vasconcelos (1851-1925), filóloga e linguista alemã radicada em Portugal, autora de A Saudade Portuguesa, e primeira mulher a atuar como docente na Faculdade de Letras da Universidade de Lisboa, em 1911.
Essa homenagem simboliza o desejo que move a equipe computacional do Lavihd: caminhar para a ponta do conhecimento valorizando a língua portuguesa e sua história, na trilha de uma ciência feita por mulheres.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}